Today I Learned
날짜
2024년 7월 5일 금요일
내용
프리커밋
하나의 레포지토리에 여러 사람이 코드를 쓰는일이야 너무나 흔하다. 사람이 쓰는 자연어야 맞춤법을 규정하는 기관이 있지만(국립국어원), 코드는 꼭 그렇지는 않다. 팀마다, 사람마다 다르다. 들여쓰기는 4칸을 쓸것인가 2칸을 쓸것인가? import 문의 순서는 어떻게 둘것인가?
왜 중요할한가? 내가 변경사항을 깃에 올렸을때, 파일 전체의 들여쓰기가 원래 2칸이였다가 4칸으로 변경됐다면? 깃허브에서 파일의 변경점을 보여줄 때 파일 전체를 보여줄거다. “유의미한, 기능상 실질적인 변화”만 보여주는 건 불가능하다. 실제로 봐야할 곳은 1줄인데, 기록상으론 파일 전체가 바뀐셈이 되버린다. 모든 들여쓰기가 2칸 늘어났기 떄문이다. 코드 리뷰 하는 사람 입장에선 도대체 어디가 바뀐건지 눈이 빠지게 찾아야한다. 나중에 커밋 기록을 보려는 사람은 도대체 어디가 바뀐건지 알 턱이없다. 특히 깃렌즈를 쓰면 더욱. 그래서 코드 맞춤법을 맞춰야한다.
우리가 쓰는 파이썬은 black이라는 코드 포맷터가 존재한다. 가장 널리쓰이는데, 파이썬 언어를 쓰는 사람끼리 쓰면 좋은 코드 맞춤법이라고 생각하면 된다. 설치하고 VS 코드 편집기에서 설정해주면 된다. 물론 위에서 예시로 든 들여쓰기 처럼, 어떤 규칙에 대해 커스텀하게 설정할 수있지만 보통 그러지 않는 편이다. 자유도가 떨어지는 만큼 모두가 동일하게 쓸 수있다.
우리팀에도 규칙이 존재했었고 적용해놨다. 그런데 어느순간부터, 내 VS코드가 엉망이 되더니 제대로 작동을 안한다. 원래 설정상, 내가 파일을 저장하면 자동으로 처리되게 해놨었는데 꼬이기 시작했다. 열심히 편집기 설정을 바꿔봤지만 작동을 안했다.다행히 팀에서 코드를 혼자 건드리게 되면서, 신경 쓸일은 없게 되었으나 고쳐야했다. 누군가 팀에 온다면 문제가 될게 분명하니까. 하지만 내 편집기는 말을 듣질 않는다.
새로운 프로젝트를 시작하면서 커밋에 적용하도록 해보았다. 내 편집기가 작동하든 말든, 새로운 사람이 설정하든 말든 결국 코드는 깃허브에 커밋해야 한다. 커밋 떄 강제하도록 설정했다. 새로운 프로젝트의 루트 디렉토리에 pre-commit 라이브러리를 설치하고 파일을 만들어줬다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# .pre-commit-config.yaml
# See https://pre-commit.com for more information
# See https://pre-commit.com/hooks.html for more hooks
repos:
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v4.6.0
hooks:
- id: trailing-whitespace
- id: end-of-file-fixer
- id: check-yaml
- id: check-added-large-files
- repo: https://github.com/psf/black
rev: '24.4.2'
hooks:
- id: black
language_version: python.3.12
rev는 버전을 의미하는데 모르겠으면 pre-commit autoupdate 를 실행하면 알아서 입력된다. 커밋 때 자동으로 적용되지만 수동으로 하고싶으면 pre-commit run 을 해보면 된다. pylint, flake8, isort 등 다양하게 추가할 수 있지만 난 다 뺴버렸다. 자꾸 멀쩡한걸 오류라고 잡아버려서…. 서로 고친걸 서로가 오류라고 우겨댄다.
파일 하나를 억지로 이상하게(?) 만들어보자.
1
2
3
4
5
6
7
8
9
10
11
12
def generate_signature(secret_key, timestamp, method, uri):
message = "{}.{}.{}".format(timestamp, method, uri)
origin_hash = hmac.new(
bytes(secret_key, "utf-8"),
bytes(message, "utf-8"),
hashlib.sha256,
)
origin_hash.hexdigest()
# 무의미한 공백 3줄을 만들었다. 기능상으론 문제없음.
return base64.b64encode(origin_hash.digest())
이상태에서 바뀐 파일을 stage 하고 pre-commit run 을 실행해보면 된다. 그럼 아래와 같은 메시지가 뜬다.
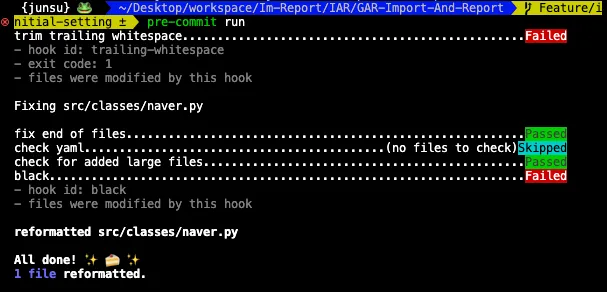
내가 설정한 프리커밋 스크립트중에 black이 실패했다는 뜻이다. 그러면 아래처럼 새롭게 편집된 버전의 동일한 파일이 나타난다.
눌러서 어느부분이 바뀌었는지 확인해보자.
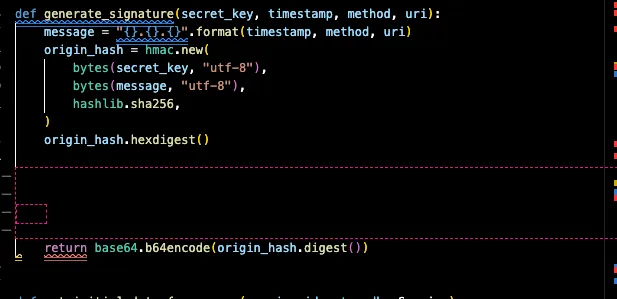
방금 만든 무의미한 공백을 알아서 지운 버전으로 파일을 변경해주었다.
이제 이 레포에 커밋하는 사람들간에, black formatter로 고생하는 일은 없겟다.
stat report
네이버 검색광고 관리자는 나의 질문에 대답해주지 않았다. 슬퍼할 시간도 없다. 빨리 대책을 찾아야한다. 현재 겪는 문제는, 데이터를 기기(PC, Mobile)로 나눠서 오지 않는다는 것이었다. 실제로 검색광고 플랫폼에는 분명 별개의 데이터가 존재하는데! 열심히 구글링했다.
다른 사람이 남긴 답을 확인해보니, /stat 엔드포인트는 단순하 값 몇개를 가져올 때를 위한 API라고 한다. 지금처럼 대규모 데이터를 많이 불러올 떄는 대용량 보고서를 이용하길 권장하고 있었다. 그럼 Docs에 좀 써놓으라고…. 3년전 글까지 뒤져서 찾았잖아..
오늘 캠페인 유형과 캠페인 명칭에 따른 세부 성과 파악 데이터를 가져와야 한다고 해보자. 그럼 데이터 기준(날짜, 기기, 캠페인 유형, 캠페인 명)과 데이터 항목(비용, 노출, 클릭, 전환수, 전환값)을 가져와야 한다. 네이버에는 여러가지 보고서 템플릿이 존재하는데 광고 성과 보고서(비용, 노출, 클릭 값이 포함)와광고성과 전환 보고서(전환수와 전환값이 포함)가 필요하다.
나는 오늘 날짜를 기준으로 광고 성과 보고서와 광고성과 전환 보고서를 만든 후 거기서 필요한 항목들을 꺼내와야 한다. 일단 보고서 만드는 API를 쏴서 만들었더니 뜬금없이 내부 데이터는 안주고 링크 하나를 준다. 직접 다운받아서 꺼내쓰라고 한다. 하…
보고서를 다운받아, 내부에서 데이터를 추출해야 한다. 이것도 쉽지 않은게
- 내가 필요로한 데이터만 있는게 아니라 찾아서 써야한다.
- 나는 캠페인 유형별이기 떄문에 그 하위항목인 광고그룹, 키워드 별로는 나뉘지 않아도 된다. 하지만 이분들은 싹다 나눠 주셨다. 따라서 동일한 캠페인에 속한 데이터들은 내가 직접 더해줘야한다.
풀어말하면, 내부에 키워드를 50개씩 가진 캠페인 2개가 있을떄, 이 보고서를 다운받으면 행이 100개라는 의미다. 난 50개씩 묶어서 더해줘야 한다. 내가 가져와야 하는 보고서는 2개니까, 이걸 두번해야 한다. 그리고 양 쪽 보고서에서 가져온 데이터를 통합해주어야 한다. 하다보니 또 신기한걸 발견했다.
광고 성과 보고서
| 캠페인명 | 비용 | 노출 |
|---|---|---|
| A | 3 | 5 |
| B | 7 | 1 |
| C | 2 | 5 |
광고성과 전환 보고서
| 캠페인명 | 전환수 | 전환값 |
|---|---|---|
| A | 7 | 20 |
| C | 8 | 30 |
이 두개를 합쳐서 총 3열로 만들어야 한다. 근데 광고성과 전환 보고서에는 B가 없다. 놀랍게도 이 네이버 친구는 API에서 반환할 때, 값이 0이면 빼고준다. 진짜 안 줄 생각은 어떻게 했을까? 대단하다.
어떻게든 할 순 있을것같은데, 이게 성능이 잘 나올려나…
회고
그래도 재밌다.