Today I Learned
날짜
2025년 2월 3일 월요일
내용
메시지 재시도
실패한 메시지를 처리하는 방법에 대한 고민이 계속되는 중…
요청이 몰렸을 때 적절하게 재시도하는 방법을 열심히 찾고 있다.
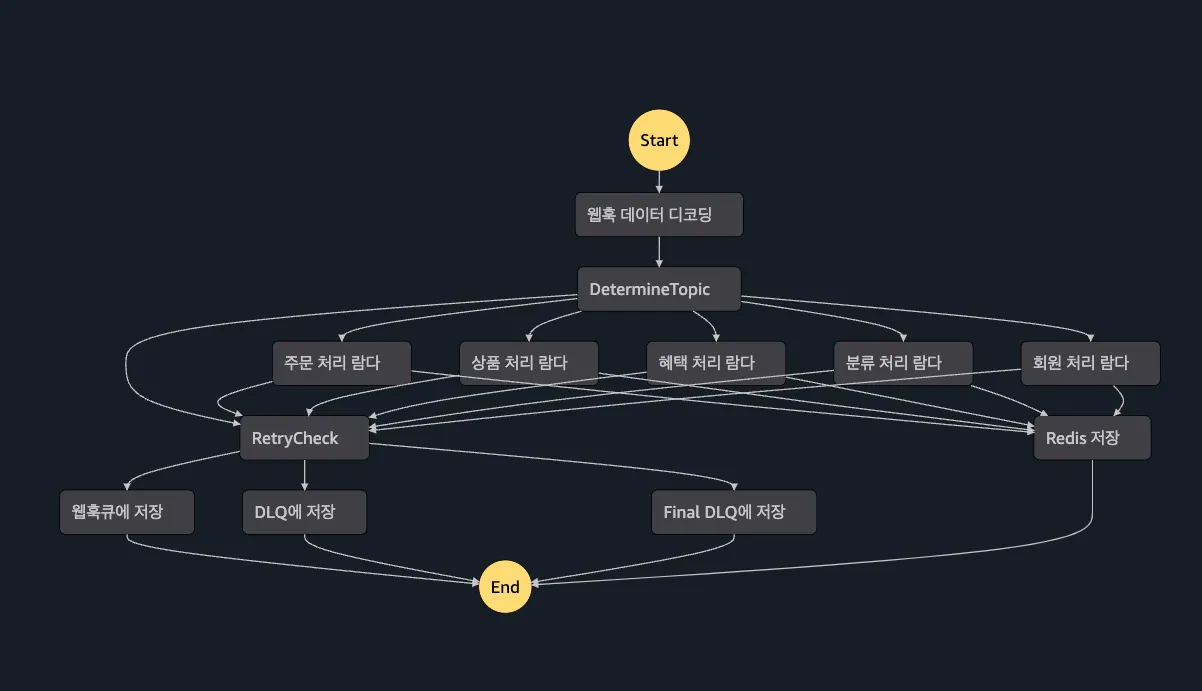
예시로 동시에 주문을 생성하는 웹훅 5천개가 들어왔다고 가정해보자. 동일한 업체의 주문은 동일한 메시지 그룹에 담기므로 1개씩 트리거 람다가 호출된다. 이 람다는 상태머신을 호출하고 종료된다. 이 과정은 매우 빨라서 3천개의 상태머신이 열리는데 몇 분이 걸리지 않는다. 카페24 API의 요청 제한이 1천개라면, 1천 개의 웹훅은 바로 처리된다. 그리고 나머지 2000개는 429 Too Many Requests를 반환받는다. 여기서부터 어떻게 처리할지를 고민하고 있는 상황이다.
지난 TIL에 말했듯 람다를 무작정 sleep 상태로 두는 것은 비용적인 측면에서도 바람직하지 않다. 초당 5개의 요청 제한이 풀린다면 모두 다 풀리는데는 2000/5 = 400초가 걸린다. 람다와 상태머신 모두 실행 시간에 비례하여 요금이 부과된다. 총 실행시간은 (12000) + (11995) +(11990) + … (15) = 401000초이므로 이만큼 비용이 더 부과된다.
우선 람다의 실행 시간을 30초로 설정했다. 30초가 지나면 람다는 무조건 종료된다. 상태머신은 실패했으므로 실패한 메시지는 SQS에서 삭제되지 않을 거라고 생각했다. 물론 아니었다. SQS가 신경쓰는 부분은 트리거로 설정된 람다까지이니 상태머신이 호출되어 트리거 람다가 종료되는 순간 메시지는 기존 큐에서 삭제된다.
리드라이브 정책(배달못한 편지 대기열)을 설정할 때 최대 수신수를 설정하면 실패한 메시지의 재시도 횟수를 조절할 수 있다. 기존 웹훅에서는 5회로 설정되있다. 5회까지 실패하고 나면 그때는 DLQ로 보낸다. DLQ는 큐에 있는 메시지를 탐색하던 중, 탐색할 메시지가 비어있을 때만 잠깐 꺼내서 처리해준다. 이걸 답습하려고 했으나 간과한 부분이 있었다. 윗 문단에서 말한것과 같은 결로, 현재 구조상 실패한 메시지의 확률이 극히 희박하기 때문이다. 거듭 말하지만 메시지의 생존 기간은 ‘상태 머신을 호출하는 람다’까지만이다. 이 호출 자체가 실패할 일은 거의 없어서 실패한 메시지가 발생할 리가 없다. 상태머신에서 실패한 메시지를 다시 큐에 넣는다고 해도, 큐 입장에선 재시도가 아니라 처음 보는 친구다. 결국 재시도가 아니게되니 무한순환에 걸린다.
그래서.. 메시지에 retry_count를 추가했다. 실패했을 때 이 수가 5를 넘기지 않으면 다시 기존 큐에 넣고, 5를 넘었으면 DLQ에 집어넣도록 했다. 나름대로 재시도 로직을 만들었다. 그럼 또 문제는.. 이 DLQ의 순환 문제를 어떻게 하냐는 것이다. DLQ를 또 트리거에 연결해서 상태머신을 호출하게 만들어놨기 때문에 이 녀석도 결국 재시도할거다.
결국 DLQ 다음으로 Really Dead Queue(가칭)을 만들었다. 10회 재시도가 넘어가면 여기 넣어놓을거다. 트리거 연결도 안해놓고 직접 확인해야한다. 10회나 실패했으면 뭔가 문제가 있는게 분명하긴하니..
그래서 더 복잡해져버렸다.
회고
제발 트래픽을 버텨다오