Today I Learned
날짜
2025년 7월 28일 일요일
내용
건강하고 빠른 웹훅을 향한 여정
입사 76주차부터 WIL을 남기지 못했다. 웹훅 이슈로 인한 실시간 데이터 처리 지연과 누락이 지속적으로 발생하고 있었기 떄문이다. WIL을 읽는 사람 입장에서 “애는 배웠다고 하는데, 웹훅 계속 박살나고 있구만 뭘 배운겨” 라는 생각이 들까봐 그랬다. 사실 이걸 쓰고 있는 지금도 마음 한구석에 괜히 사망 플래그를 세우는 건 아닌지 걱정이 되지만, 더 미루면 영영 회고를 하지 못할까봐 지금이라도 이 여정을 정리하는 글을 쓰려고 한다. 제 부족한 실력으로 괜한 피해를 입은 분들(사실상 샐러드랩 모두)께 죄송스러운 마음을 가지며 글을 시작하고자 한다.
웹훅은 무엇인가
웹훅은 웹 개발에서 사용자 정의 콜백을 사용하여 웹 페이지 또는 웹 애플리케이션의 동작을 강화하거나 변경하는 방법이다. 더 쉽게 말하면, 카페24에서 ‘데이터 바뀌었어요~’라고 말해주는 요청이다. 쇼핑몰 관리자가 카페24에 접속하여 자신의 쇼핑몰에 있는 상품의 가격을 수정하면 카페24는 우리 서버에 ‘A 쇼핑몰의 (가) 상품이 수정되었단다’ 라고 말해준다. 그러면 우리 서버는 카페24에게 ‘A 쇼핑몰의 (가) 상품에 대한 모든 데이터’를 요청하여 정보를 받아 저장한다. 이 과정을 통해 알파리뷰 대시보드와 카페24 어드민 페이지에서 (가) 상품의 가격이 동일하게 나온다. 그렇다면 웹훅을 처리하는데 있어 특히 신경써야 할 부분은 무엇인가?
정확성
데이터는 정확히 반영되야하고, 누락되어선 안된다. 생성한 주문이 배송완료되었다는 웹훅이 처리되지 않고 누락되면 해당 주문의 고객은 리뷰를 달 수 없다. 특정 상품에 혜택이 적용될 때 할인될 금액이 1000원이 10000원이 되어선 안된다. 변경된 데이터는 정확하게, 빠지지 않고 반영되어야 한다.
신속성
일부 데이터들의 경우는 실시간으로 반영되어야 한다. 오늘 바꾼 혜택의 적용 금액이 내일부터 적용된다거나 방금 가입한 고객 데이터가 처리되지 않아 첫 구매 할인 혜택을 받을 수 없게 된다거나.. 즉각적으로 반영되어야 할 데이터는 최대한 빠르게 반영되야 한다.
순서
상품삭제 웹훅이 상품 생성 웹훅보다 먼저 들어온다면? 고객의 회원가입 웹훅보다 주문 웹훅이 먼저 들어온다면? 사실 데이터 저장 과정에서 어느정도 관련된 상황을 다루긴 하지만 예상치 못한 곳에서 데이터가 부정확해질 수 있다.
API 요청 속도
카페24라서 존재하는 문제이자, 만악의 근원. 종양 그자체. 모든 사태의 원흉. 히틀러. 내성발톱. 카페24가 보내는 웹훅에는 ‘누구의 정보가 변경되었는가’에 대한 데이터만 있다. 바뀐게 설명인지 이름인지 가격인지는 카페24에 요청을 보내 정보를 조회해서 우리 데이터와 비교해봐야 알 수 있다. 근데 이 요청에는 속도 제한이 있다. 이 제한의 범위는 특정 쇼핑몰의 요청 종류이다. A 쇼핑몰은 상품 관련 API를 너무 많이 보내 제한에 걸려도 A 쇼핑몰의 주문 관련 API에는 영향이 없다. 한 쇼핑몰이 사용할 수 있는 요청 제한 수는 1000개이며, 이 횟수는 1초당 5개씩 회복된다. 이 횟수 이상으로 요청을 보내면 카페24는 데이터를 반환하지 않고 응답을 실패처리한다. 이 실패가 너무 많아지면 이메일이 온다.
왜 바꾸어야 하는가
이렇게 중요한 웹훅을 왜 괜히 들쑤셔야 할까? 기존 처리 방식은 속도 측면에서 명확한 한계가 있었기 때문이다.
기존 버전의 웹훅은 EC2라는 서버에서 동작하는 커맨드로 처리한다. 웹훅 메시지가 가득 담겨있는 주머니에서 메시지를 한 주먹씩 꺼내서 처리한다고 생각하면 된다. 처리속도는 얼마나 빠르게 메시지를 꺼내 처리하는 지와 몇개의 손이 주머니에 접근하는지에 따라 결정되는데 이건 곧 EC2의 성능(돈)을 의미한다. 메시지를 꺼내는 속도를 쌓이는 속도보다 빠르도록 유지하기 위해 EC2 성능을 계속 신경써줘야 하고 들어가는 시간과 돈이 문제였다.
뿐만 아니라 기존 시스템은 속도를 유동적으로 조절할 수 없었기 떄문에 웹훅을 처리사이에 0.2초의 간격을 두었다. 1초 당 회복되는 API 버킷수인 5개를 염두해둔 설정이다. 처리 자체에 소요되는 시간 + 0.2초 간격으로 인해 API 요청 버킷을 소모하는 속도가 회복하는 속도를 따라잡을 일은 없다. 이 설정은 허용된 버킷 수를 초월하는 요청을 처리할 땐 안전할 수 있지만 그보다 적은 갯수를 빠르게 처리하는데는 분명 불필요하다. 웹훅 1000개를 동시에 처리해야 하는 상황이라면 대기시간 없이 처리하는 방식보다 0.2초 * 999 = 199.8초 더 걸린다.
설계
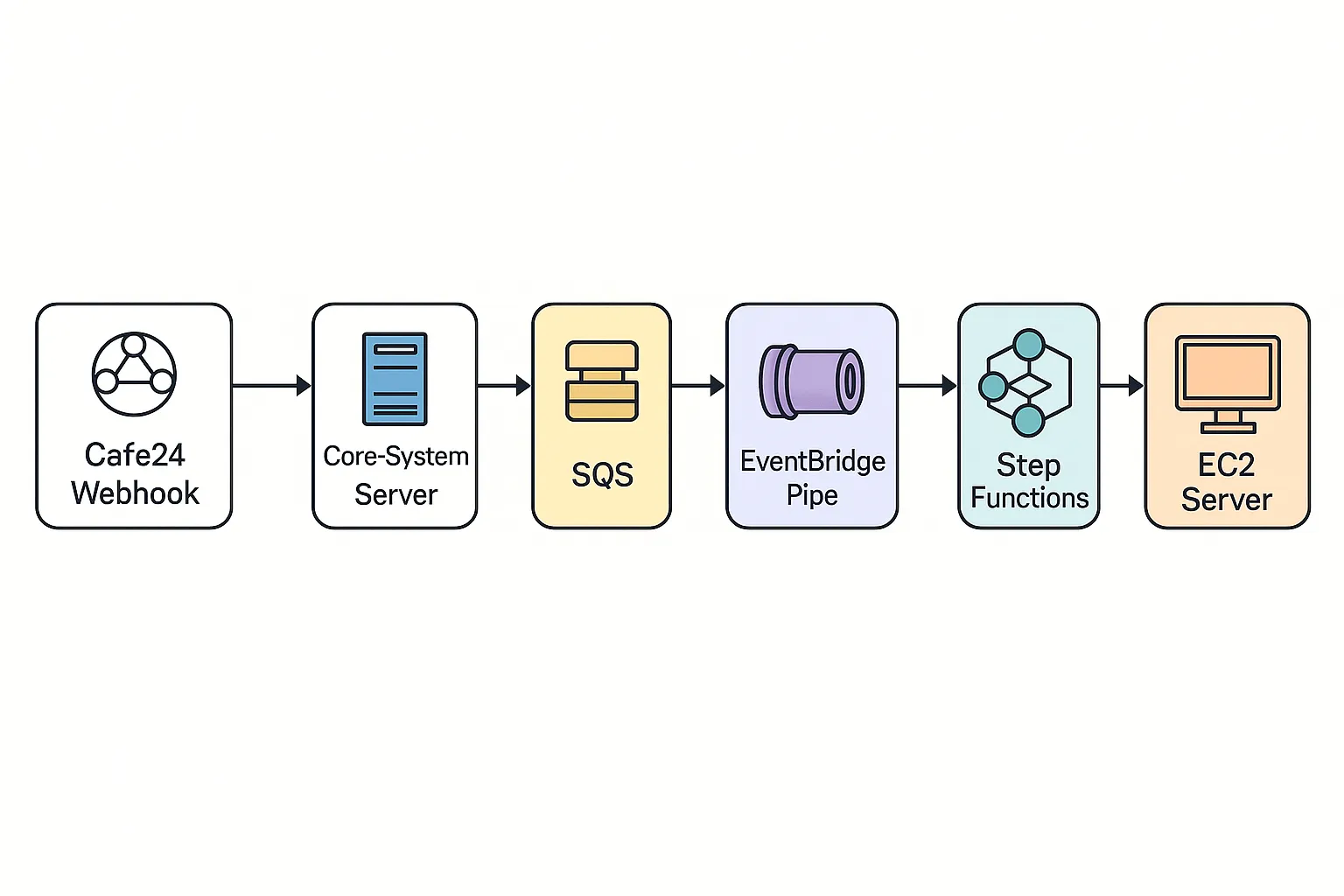
웹훅이 처리되는 전체 과정. GPT 녀석이 자꾸 ElastiCache는 빼먹는다.
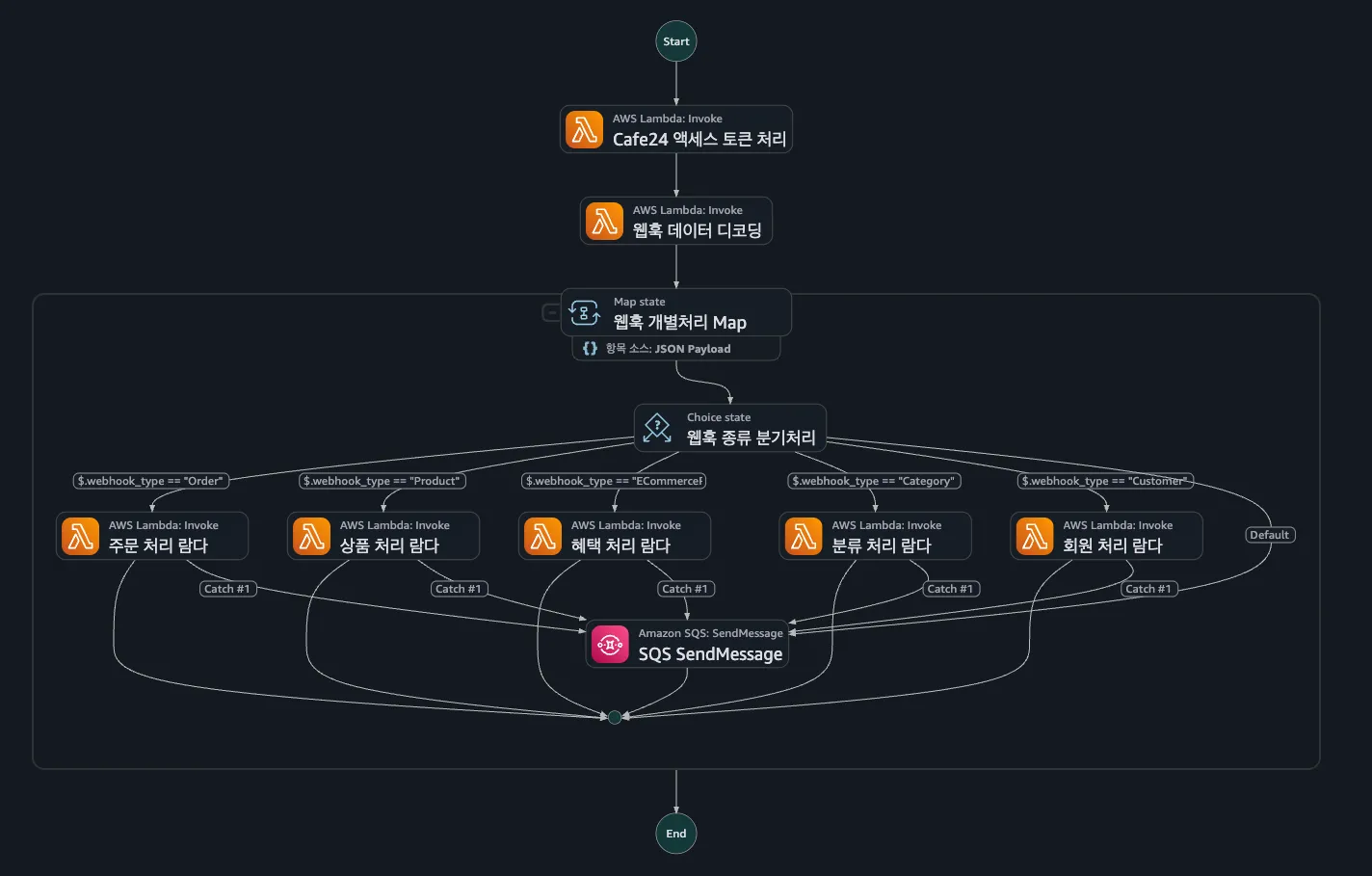
Step Functions 내에서 이뤄지는 데이터 처리의 흐름
SQS FIFO Queue
SQS 큐는 일반 큐와 FIFO 큐 두 종류가 있다. FIFO는 First In First Out이라는 뜻으로, 선입선출이 보장되는 큐라는 의미다. FIFO 큐에는 메시지 그룹을 설정할 수 있는데, 같은 그룹 내에서만 선입선출이 적용된다. 주머니 내에 빨간색 메시지 그룹, 파란색 메시지 그룹 등으로 나뉘어져 있다고 생각하면 편하다. 메시지를 꺼내는 손이 여러 개 때에도 하나의 그룹에 접근할 수 있는 손은 반드시 하나다. 어떤 손이 빨간색 메시지를 가져가서 처리중이라면 다른 손은 절대 빨간색 메시지에 손 댈 수 없다. 이 덕분에 각 쇼핑몰 별로 메시지 그룹을 나눠놓는 다면 같은 쇼핑몰의 메시지가 처리되는 순서를 보장할 수 있다. 그룹에서 가장 나이 많은 메시지가 처리되기 전까지 다른 메시지들은 처리되지 않는다.
이것을 바꿔말하면 앞의 메시지가 제대로 처리되지 않을 경우 해당 쇼핑몰의 웹훅 처리 과정이 마비될 수 있다는 의미이다. SQS는 한 번 처리된 메시지가 다른 소비자에게 다시 처리되도록 시도하기 까지의 시간을 설정할 수 있는데 이 시간동안에는 해당 그룹 내에 메시지는 그 어떤 것도 처리될 수 없다. 가장 오래된 메시지의 ‘처리’는 ‘삭제’를 의미하기 때문이다. 모종의 이유로 삭제되지 못한 메시지를 계속 반복하여 재시도하는 것은 메시지의 누적을 의미하므로 절대 바람직 하지 않다. 따라서 실패한 메시지를 다른 곳에 저장하고 삭제해주어야 하는데 이를 DLQ(Dead Letter Queue)라고 한다.
메시지 그룹이라는 개념은 여러 쇼핑몰의 웹훅을 별개로 병렬하게 처리하는데도 필수적이다. 메시지 그룹별로 FIFO가 유지되지 않는 상황에서 특정 쇼핑몰에 메시지가 많이 몰렸다고 가정해보자. 빨간색 메시지가 10만개, 파랑색 메시지가 50개, 초록색 메시지가 10개 있다면 빨간색 메시지만 계속 처리되느라 상대적으로 적은 주황색 메시지와 초록색 메시지가 제시간에 처리될 확률은 낮아진다. 주머니 내에서 별도로 관리된다면 빨간색 메시지가 아무리 많이 들어온다고 한들, 다른 메시지들은 별도로 제 시간에 처리될 수 있다. 이 규칙은 특정 경우에 무력화될 수 있는데 후술하겠다.
Step Functions
SQS에 쌓이는 웹훅 메시지를 빠르고, 독립적으로 처리할 수 있는 시스템이 필요했고 나는 Step Functions를 이용하기로 했다. 이 서비스는 AWS 내 다양한 서비스를 이용한 플로우를 관리해주는 서비스이다. 웹훅의 처리 과정을 여러 단계로 나누었고 각 웹훅 종류별로 별도의 함수로 처리하도록 구현했다.
SQS에서 받아온 메시지는 다음 순서대로 동작한다.
- 데이터 조회를 위한 Cafe24 토큰 조회 + Lock 확인
- 카페24 API로 데이터 조회 + 요청의 헤더에서 버킷을 확인하고 필요할 경우 Lock을 설정
- Redis 데이터 저장
이 과정 중 실패한다면 DLQ로 이동한다.
1번 함수에선 해당 쇼핑몰에 대한 락이 걸려있는지 확인하고 2번 함수에선 락을 확인하는 과정이 있기 떄문에, API 요청 속도는 너무 빠르지 않도록 조절된다.
ElastiCache
최초에는 저 람다 함수에서 데이터베이스에 직접 저장하려고 했다. 하지만 데이터를 저장하는 위치가 서버외에 또 존재할 경우 관리소요에 대한 부담이 발생할 수 있어서 캐시서버에 저장하도록 변경했다. 이후 EC2 서버에서 이 캐시에 저장된 데이터를 꺼내 저장하는 커맨드를 돌렸다. ‘커맨드가 동작하여 저장하는 방식이라면 기존과 차이가 있을까?’라고 생각할 수 있으나 HTTP 요청을 보내고 저장하는 것과 데이터를 그냥 입력하는 것은 부하나 속도에 엄청난 차이가 있다.
사건사고
개발 과정에서 정말 많은 일이 있었다. 하루하루 고치고 원인 찾느라 너무 힘들어 기록도 잘 남기지 못했지만 기억을 더듬어보려고 한다.
메시지 그룹의 무력화와 병목
3월 중순에 겪은 첫 대참사. 당시 웹훅 저장 큐가 쌓이는 속도가 급격히 늘어나 200만개가 쌓였고, 데이터 처리가 지연되어 온갖 문의가 인입되었다. 원인은 당연히 비정상적으로 많이 발생하는 일부 업체들의 웹훅이다. 특정 업체들의 경우 하루에 10만개 가까운 상품 수정 웹훅을 발생시키는데, 이 웹훅이 제대로 처리되지 못했다.
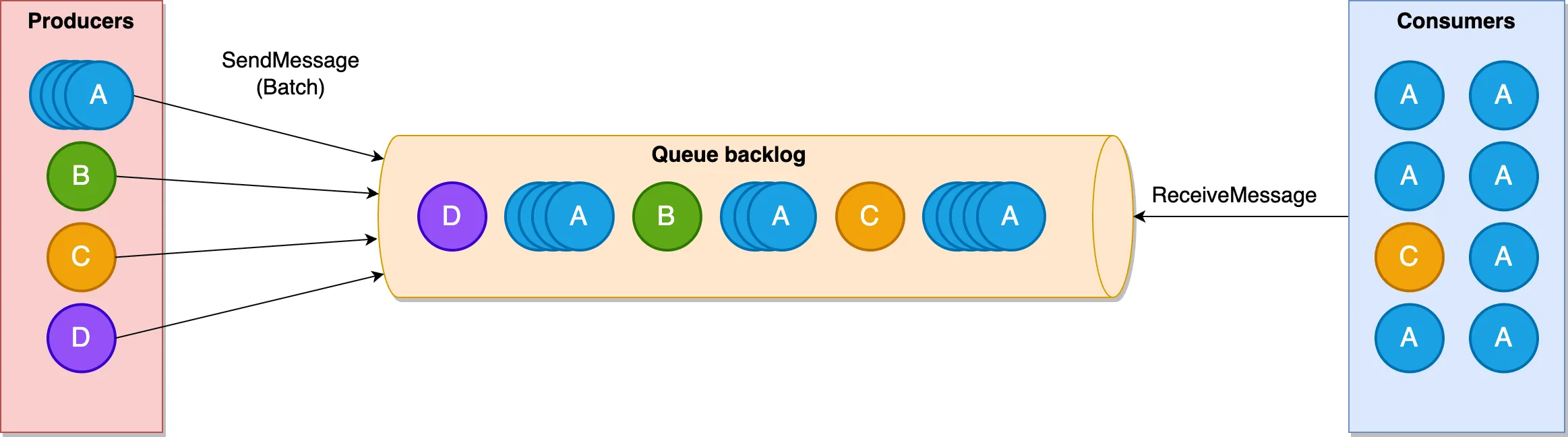
이 사태로 알게 된 것은 메시지그룹 간의 독립성이 그 어떤 경우에도 보장될 정도는 아니라는 것과, 그것이 ReceiveMessage의 작동 방식 때문이라는 점이었다. 나는 SQS의 메시지 그룹을 쇼핑몰 별로 구분했기 때문에 어떤 쇼핑몰에서 웹훅이 과도하게 발생하더라도 다른 그룹의 메시지의 플로우에는 영향이 없을 거라고 판단했다. 이 오착은 SQS Queue와 매핑된 Eventbridge Pipe가 큐에서 메시지를 꺼낼때 호출하는 ReceiveMessage가 ‘그룹별’로 작동하지 않는다는 사실을 몰라서 발생했다. 메시지가 그룹별로 분리되어있다고 하더라도, 가장 수명이 오래된 메시지를 선택하고 해당 메시지가 선택한 그룹에서 최대한 많은 메시지를 꺼내려고 한다(참조문서). 위 사진에서 맨 앞에 가장 오래전에 들어온 A가 생산한 메시지가 40만개라고 생각해보자. C가 생산한 메시지는 별도의 조치가 없다면 앞서 추가된 40만개의 A 메시지가 처리되고 나서야 처리될 것이다.
따라서 메시지를 많이 발송하는 업체에 대한 조치가 필요했고, 지속적으로 웹훅을 많이 발생시키는 업체들을 블랙리스트로 관리했다. 애초에 해당 쇼핑몰의 메시지는 큐에 넣지않고 버리는 대신, 해당 업체는 직접 주기적으로 전체 마이그레이션 처리해준다. 현재는 이 과정을 자동화하는 로직을 개발하여 테스트 중에 있다.
실패한 메시지의 동일 큐 삽입
하나의 웹훅이 여러 번 처리될 수 있도록 재시도 횟수가 3회 이하인 메시지는 기존 큐로 돌려보내고, 5회 이하에는 DLQ로 보냈다. 람다에서 실패하더라도 상태머신은 성공한 것으로 판단하도록 설계했다. 이로인해 메시지는 삭제되지만, 이 메시지를 직접 기존 큐에 다시 넣었다. 실패한 메시지(시스템 입장에선 성공)가 동일한 큐에 삽입될 경우, 헤더에 있는 메타데이터로 인해 예상치 못한 동작이 발생할 가능성이 높다. 현재는 메시지 처리가 실패하면 상태머신도 실패로 판단하여 큐에서 메시지가 삭제되지 않는다. 이로 인해 특정 메시지가 실패하면 해당 그룹의 소비 자체가 멈추기 때문에 선입선출이 깨지는 문제도 자연스레 해결되었다.
멀티쓰레딩 처리 실패
새로운 웹훅 시스템을 만들면서 충분히 빠른 속도를 보장하기 위해 병목에 대해서 많이 고민했다. 큐와 Step Functions이 호출되는 부분을 가장 신경썼고, 그룹 별 메시지 갯수만 관리된다면 여기서 병목은 발생하지 않았다. ElastiCache에 저장된 데이터를 DB에 저장하는 곳에서 병목이 일어날거라고는 예상하지 못했다. 그냥 데이터에서 필요한 것들만 알맞은 필드에 저장하는 로직이니까. 하지만 Step Functions이 쌓아주는 속도에 비해 많이 부족했다. 기존에는 모든 데이터를 하나의 리스트에 넣었고 0번 index부터 하나씩 pop해서 저장하는 형태였기 떄문에 점차 쌓여갔다.
Redis에 쌓인 데이터를 처리해주는 컨슈머의 갯수를 늘릴 필요가 있으나 하나의 리스트를 여러 컨슈머가 처리하는 것은 위험성이 있다고 판단해서 리스트를 여러개로 분리했다. 당시에는 shop_id의 최대가 이제 11000을 넘는 수준이라, 리스트를 11개를 만들고 shop_id를 1000으로 나누었을 때의 몫을 기준으로 나누어주었다. 0~999번은 0번리스트 , 1000~1999번 샵은 1번리스트 이런식이다. 나중에 서비스가 커져 shop_id가 몇 만개 단위가 된다면 다시 한번 정리할 필요는 있겠다.
여러 리스트에서 데이터를 가져와 저장하는 방식을 멀티쓰레드로 구현했는데 실제로 저장이 안되는 이슈가 발생했다. 당시에는 상황이 너무 급박해서 정확한 원인은 파악하지 않고 반복문으로 리스트마다 돌면서 처리하는 작업으로 변경해놨다. 이 부분도 앞으로 규모가 더 커지기 전에 처리해야하는 부분이긴 하다.
Eventbridge Pipe의 batch 처리
새 웹훅으로 처리하는 업체의 수가 늘면서 속도를 개선해야 했다. 큐에서 메시지를 가져오는 Eventbridge Pipe는 한번에 가져올 메시지의 수를 최대 10개까지로 조정할 수 있다. 이 설정을 기존 1에서 10으로 늘렸는데, 이 때 가져오는 메시지가 모두 동일 그룹일 거라고 안일하게 생각했다. Pipe로 가져온 메시지 10개는 하나의 Step Functions으로 처리된다. 메시지에 담긴 웹훅의 종류(고객, 주문 등)에 따라 각기 다른 람다가 호출되야 하는데 나는 10개 중 앞의 것으로 전부 같은 타입인 것으로 간주하고 처리하도록 해놨다. 실제론 10개가 반드시 같은 그룹에서 가져오는 것은 아니기 떄문에 메시지 10개의 종류가 같지 않을 경우 제대로 처리되지 않았다.
결국 Step Functions에 있는 Map State 분기로 처리하여 해결했다. 같은 상태머신 내에서 메시지마다 반복문을 돌면서 각기 다른 분기를 타 별도로 처리된다.
Eventbridge Pipe 매핑 갯수
하나의 파이프는 동시에 몇 개의 메시지 그룹에서 메시지를 가져올까? 이 고민을 너무 늦게 했다. 처리되는 쇼핑몰이 10000개 이상이고 웹훅의 종류는 5개이므로 실제로 존재하는 메시지 그룹은 50000개 이상이다. 모든 그룹의 메시지가 들어있을 때 파이프는 모든 그룹을 동시에 병렬하게 처리하지 못하고 있었다. 메시지 그룹이 워낙 많으므로 파이프를 12개로 늘려서 동시에 처리되는 메시지 그룹의 수를 늘렸다. 하나의 파이프가 접근하여 처리하고 있는 메시지 그룹에는 다른 파이프가 접근하지 못하기 때문에 가능했다.
duplication_id
4월 ~ 5월에 미친듯이 발생한 주문 누락의 원인.. 큐에 메시지를 삽입할 때 메시지 그룹을 설정하고 message_duplication_id를 설정해주어야 한다. 이 값이 같은 메시지가 5분 내에 중복하여 들어올 경우, 해당 메시지는 큐에 진입하지 못하고 삭제된다. 따라서 각 메시지는 고유한 duplication_id를 가져야 한다. 기존에는 현재시간의 timestamp 값을 이용해서 이 부분을 처리하고 있었는데 코드에서 이 부분이 삭제되어 있었다. 그래서 모든 메시지가 {shop_id}_{event_type}_None 으로 들어가고 있었다. 즉 하나의 쇼핑몰에서 하나의 웹훅 이벤트타입은 5분에 하나만 처리되고 있었다. 3주 동안 찾아 헤맨 웹훅 누락의 원인이어서 발견하자마자 카페에서 소리를 질렀다.
SQS Queue에 batch 삽입
매일 새벽 5시 30분 쯤, 주문 배송상태 변경 웹훅이 5만 개 가까이 들어온다. 각 메시지를 하나씩 큐에 집어넣으면 boto3 메서드에서 쓰로틀 에러가 발생할 뿐더러, 서버 부하까지 발생하고 있었다. 10개씩 메시지를 삽입할 수 있는 batch 메서드가 있어서 변경해주었다. 하나의 요청에 여러 웹훅이 담기는 경우(주문과 상품의 일괄변경)에는 이 메서드를 이용하도록 변경했다.
개선해야 할 점
EC2 소비 방식
여러 문제가 있다. 일단 코어 EC2가 주기적으로 다운되던 경우(최근에는 안그러지만)가 있는데 그럴때마다 다시 들어가서 켜줘야 한다. ECS에서 동작시키는 것도 고려했으나, 처리한 웹훅을 파일시스템에 로그 형식으로 남기고 있어 문제였다. ECS에선 컨테이너가 꺼지면 로그파일이 당연히 사라지고 S3로 남기자니 별도로 작업이 필요한 상황이기 때문이다.
1만개가 넘는 쇼핑몰의 웹훅 정보를 고작 10개의 리스트에 담고 있어 피크타임때는 병목이 있다는 것, 데이터 컨슈머 2개가 개별적으로 커맨드를 돌리는 상황이라 아직 멀티쓰레딩으로 효율적으로 처리하고 있지 못하고 있는 점도 고쳐야한다.
블랙리스트
쇼핑몰 중 비정상적으로 웹훅을 많이 보내는 업체들이 종종 있다. 상품 수정을 매일 5만 개 ~ 10만개를 하는 업체들이 있는데, 이 웹훅을 모두 처리하면 전반적인 처리 시스템에 부하가 걸린다. 현재는 해당 쇼핑몰들의 웹훅을 처리하지 않고 수동으로 마이그레이션을 돌려주고 있다. 이걸 까먹어서 문제가 된 경우도 저번주에 있었고.. 현재 일정 기간동안 웹훅 처리 갯수를 확인하여 기준 이상일 경우 웹훅을 받지 않는 것, 웹훅을 받지 않는 업체는 매일 밤 자동으로 마이그레이션을 돌려주는 기능이 테스트 중이다. 이 기능이 정상적으로 빠르게 도입되어야 안정화가 될 듯 하다.
서버와의 분리
현재 웹훅의 처리 시작점은 요청을 받아 큐에 메시지를 넣어주는 것은 서버다. 웹훅이 폭증할 경우 서버에 영향을 미치고 있기 때문에 언젠가는 이 부분을 분리할 필요가 있다고 생각한다. 큐에 넣어주는 동작만 할지, 처리 자체가 거기서 모두 이뤄질지는 모르겠으나 서비스 안정에 영향을 안끼치는게 최우선이기 때문이다.
느낀 점
나를 죽이지 못하는 고통은 날 강하게 만든다.
난 이 말을 ‘살아남은 것만으로도 강해진다’는 의미로 생각 했는데, 알고보니 살고 싶으면 강해지라는 뜻이었다. 매일 매일 ‘내일은 몇 번 슬랙에서 태그당할까’, ‘난 개발할 자격이 없는건 아닐까’, ‘내가 다른사람이었다면 나에게 욕을 박았을텐데’ 생각에 진짜 회사가기 싫고 잠도 못자고 힘들었는데.. 어떻게 버텨내고 성공해냈다. 내 부족함 떄문에 다른 사람들이 피해보는게 참 힘들었다. 민폐끼치기 싫으면 열심히 하지말고 잘 해야한다고 많이 느꼈다.
무엇이 날 빡치게 만들까
한참 오류의 원인을 찾지도 못하고, 찾아도 새로운 오류에 미치기 일보 직전일때 리드분께 면담을 진행해서 들은 조언이었다. 내가 만들 이 기능이 언제 날 가장 화나게 할 것인가? 언제 어디서 데이터가 처리되지 않고 있는지를 모를때였다. 웹훅이 처리되지 않은 것이 큐에 진입하지 못한 것인지, 람다에서 실패한 건지, EC2에서 실종된 것인지를 모르니 원인을 찾는게 너무 힘들고 고달팠다. 애초에 생각하고 이에 대한 대책을 마련했어야 했다. 뒤늦게 모든 과정을 데이터독 로그에 남기도록 하고 나서야 모든 원인이 해결되었다. 새로운 기능을 디자인할 때는 이 깡통이 날 화나게 만들 시나리오는 무엇인지 항상 생각하자.
충분히 생각하고, 추정하지 말자
이 기능을 만들면서 심사숙고하지 못해 뒤늦게 추가하게 된 점이 너무 많다. 처음에는 Step Functions을 Pipe로 매핑하는 것을 몰라 람다에서 Step Functions을 호출하도록 해놨다. 빠른 처리를 위해 Express 타입으로 생성된 Step Functions은 함수로 호출할 떄 응답값으로 실행 결과를 알려주지 않는다. 따라서 앞선 메시지의 처리 결과를 알 수 없을 뿐더러 앞선 메시지가 상태머신에서 처리되는 동안 후속 메시지 처리를 위해 호출된 상태머신이 먼저 처리될수도 있다. 이 뿐만 아니라 속도 조절을 위한 락도 생각하지 못했고, Redis에서 데이터를 저장하는 곳에 발생할 병목도 고려하지 못했다. 뒤늦게 부랴부랴 추가하는 것이 많다 보니 구현이 정확하지 못했고 문제가 문제를 불러일으킨 경우가 참 많았던 것 같다. 세상만사가 뜻대로 되는 게 하나 없다지만, 그렇다고 계획이 필요 없다는 뜻은 절대 아니다.