2023년 8월 3일 알고리즘 문제풀이
백준 1991
1차 시도
나의 생각
왼쪽 자식이 존재하면 재귀를 통해 들어가고, 없을 때 오른쪽 자식도 확인하는 과정을 거쳤다. 정답을 위한 배열에 왼쪽 자식과 부모, 오른쪽 자식을 어느 타이밍에 추가해야할 지 헷갈렸고 이로 인해 코드를 완성하지 못했다.
결과
오답
코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
import sys
arr = []
n = int(sys.stdin.readline())
for _ in range(n):
p, l, r = sys.stdin.readline().rstrip().split()
arr.append([p, l, r])
front = ['A']
mid = []
back = []
def search_front(node, arr, ans):
for x in arr:
if x[0] == node[0]:
if x[1] != '.':
ans.append(x[1])
search_front(x, arr, ans)
if x[2] != '.':
ans.append(x[2])
search_front(x, arr, ans)
def search_mid(node, arr, ans):
for x in arr:
if x[0] == node[0]:
if x[1] != '.':
search_mid(x, arr, ans)
else:
ans.append(x[0])
if x[2] != '.':
search_mid(x, arr, ans)
break
def search_back(node, arr, ans):
for x in arr:
if x[0] == node[0]:
if x[1] != '.':
search_back(x, arr, ans)
else:
ans.append(node)
if x[2] != '.':
search_back(x, arr, ans)
ans.append(x)
ans.append(node[0])
search_front(arr[0], arr, front)
search_mid(arr[0], arr, mid)
search_back(arr[0], arr, back)
print(front)
print(mid)
print(back)
2차 시도
나의 생각
정답을 위한 배열에는 항상 부모만 넣는다는 기준을 세웠다. 또 왼쪽자식과 오른쪽 자식의 탐색을 if-else 조건문을 사용하였는데 별개로 하였다. 즉 왼쪽 자식을 먼저 탐색해 존재하면 재귀를 통해 최대한 깊숙히 들어간 후 더이상 왼쪽자식이 존재하지 않을 때 그 때의 부모노드를 배열에 추가하면 전체 트리에서 가장 왼쪽에 있는 노드를 배열에 추가한 것으로 구현된다는 것을 깨달았다. 순회의 방식에 따라 왼쪽 자식 탐색, 부모노드 삽입, 오른쪽 자식 탐색의 순서만 변경해주었다.
결과
정답
코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
import sys
arr = []
n = int(sys.stdin.readline())
for _ in range(n):
p, l, r = sys.stdin.readline().rstrip().split()
arr.append([p, l, r])
front = []
mid = []
back = []
def search_front(node, arr, ans):
ans.append(node[0])
if node[1] != '.':
for x in arr:
if x[0] == node[1]:
search_front(x, arr, ans)
break
if node[2] != '.':
for x in arr:
if x[0] == node[2]:
search_front(x, arr, ans)
break
def search_mid(node, arr, ans):
if node[1] != '.':
for x in arr:
if x[0] == node[1]:
search_mid(x, arr, ans)
break
ans.append(node[0])
if node[2] != '.':
for x in arr:
if x[0] == node[2]:
search_mid(x, arr, ans)
break
def search_back(node, arr, ans):
if node[1] != '.':
for x in arr:
if x[0] == node[1]:
search_back(x, arr, ans)
break
if node[2] != '.':
for x in arr:
if x[0] == node[2]:
search_back(x, arr, ans)
break
ans.append(node[0])
search_front(arr[0], arr, front)
search_mid(arr[0], arr, mid)
search_back(arr[0], arr, back)
print(*front, sep='')
print(*mid, sep='')
print(*back, sep='')
백준 5639
1차 시도
나의 생각
전위 순회가 주어졌으니 앞뒤 노드간의 차이 비교를 통해 원래 트리의 모습을 구현하고자 하였다. 현재 노드가 이전 노드보다 작다면 BST(binary search tree)의 성질 상 왼쪽 서브트리에 포함된다고 생각했다. 현재노드가 이전노드보다 커질 경우 바로 직전의 오른쪽 자식이 아니라, 이전으로 되돌아가다가 현재노드보다 더 큰 노드를 만난다면 그 노드의 왼쪽자식의 오른쪽 자식일것이라고 생각했다. 더 쉽게 설명하자면
- 현재 노드는 이전 노드보다 크기가 커졌으니 누군가의 오른쪽 자식일 것이다.
- 이전 노드들을 탐색한다.
- 어떤 이전 노드가 현재 노드보다 크다.
- 그렇다면 현재 노드는 어떤 이전 노드의 왼쪽 서브트리 안에 있다.
- 하지만 어떤 이전 노드의 왼쪽 자식은 현재 노드보다 작다.
- 따라서 어떤 이전 노드의 왼쪽 자식의 오른쪽 자식이다.
이와 같은 논리이다.
근데 결국 원래 트리를 구현하고 이를 바탕으로 후위 순회를 출력하려는 방법은 실패했다. 우선 원래 트리로 복구하지 못했고, 하더라도 이중 반복문이고 입력 크기가 10^4라 시간초과가 뜰것이란걸 뒤늦게 깨달았다.
결과
오답
코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
import sys
arr = []
while True:
num = sys.stdin.readline().rstrip()
if not num:
break
arr.append(int(num))
n = len(arr)
tree = [[arr[0],0,0]]
tree = [[0, 0, 0] for _ in range(n-1)]
for i in range(1,n):
tree[i][0] = arr[i]
if arr[i-1] > arr[i]:
tree[i-1][1] = arr[i]
else:
tmp = arr[i+1]
for j in range(n-1):
if arr[j] < tmp:
tree[j][2] = tmp
break
print(tree)
2차 시도
나의 생각
그 외의 방법은 전위 순회와 후위 순회의 순서의 차이에 따라 직접 변경하는 것이라고 생각했는데, 너무 어려웠다. 따라서 정답을 보고 이해했다. 원리는 다음과 같다.
함수를 정의한다. 이 함수는 left+1부터 right까지 주어진 전위 순회의 결과를 탐색하다가 left보다 값이 더 클 때를 찾는다. 그때를 mid로 설정한다. mid 전까지는 모두 왼쪽 서브트리에 속한다. 그 이후는 오른쪽 서브트리이다. 이를 바탕으로 재귀함수를 이용한다. 후위순회의 순서대로
- 왼쪽 서브트리 재귀
- 오른쪽 서브트리 재귀
- 더이상 타고갈 노드가 없다면 현재 노드 출력
로 코드를 작성하여 후위순회 결과를 출력한다.
또, 입력크기가 주어지지 않았는데, try-except문을 잊고 있어서 이 부분도 꼭 알아야겠다. 나는 num의 입력값이 False면 break 하도록 했는데 오답처리되었다..
mid = right + 1을 쓰는 이유는 주어지는 트리가 오른쪽 자식이 없을 때를 위해서다. 루트 가 왼쪽 자식만 있다면, mid가 따로 설정되지 않는다. 루트보다 큰 노드가 없기 떄문이다. 따라서 두번의 재귀 중 두번째는 오른쪽 서브트리 탐색을 위한 재귀인데, 이 함수가 문제가 된다.
결과
이해
코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
import sys
sys.setrecursionlimit(10**6)
arr=[]
while True:
try:
num=int(sys.stdin.readline())
arr.append(num)
except:
break
def search(left,right):
if left>right:
return
else:
mid=right+1
for i in range(left+1,right+1):
if arr[left]<arr[i]:
mid=i
break
search(left+1,mid-1)
search(mid,right)
print(arr[left])
search(0,len(arr)-1)
백준 1197
1차 시도
나의 생각
최소 스패닝 트리에서 어떤 내용이 들어있었는지 전혀 기억이 안난다… 이 참에 잘 알아놓고 추가 관련 문제좀 풀어봐야 겠다. bfs, dfs로 풀어볼까 하다가 전혀 아닌것 같아서..
결과
오답
코드
1
2
3
4
5
6
7
8
9
10
11
import sys
v,e = map(int,sys.stdin.readline().split())
graph = [[0 * v] for _ in range(v)]
for _ in range(e):
a,b,c = map(int,sys.stdin.readline().split())
graph[a][b] = c
graph[b][a] = c
visited = [False * v]
2차 시도
나의 생각
기억에는 전혀 없지만 분명 이전에 풀었던 문제라 이전 블로그 기록을 찾아봤더니 있다! 네이버 블로그 시절에 썼다가 옮겨온 글이라 형식이 망가지긴 했지만.. (링크) 그래서 추가적으로 자료를 가져와 보충했다. 출처
이 최소 스패닝 트리 문제는 크루스칼 알고리즘(Kruskal Algorithm)을 사용하여 해결한다. 크루스칼 알고리즘의 과정은 다음과 같다.
- 모든 간선을 가중치 오름차순으로 정렬한다.
- 가중치가 가장 낮은 간선부터 순회하면서,
- 이 간선이 추가된다면 사이클을 발생시키는지 확인한다.
- 사이클을 발생시킨다면,
continue - 사이클을 발생시키지 않는다면 추가한다.
- 사이클을 발생시킨다면,
결과로 도출되는 추가된 간선들이 최소 신장 트리이다. 사이클이란 시작점과 끝점이 같은 경로를 의미한다.
그런데 spanning tree는 사이클이 없이 모든 정점이 연결되어 있는 그래프이다. 따라서 사이클이 발생하는지 확인해야 한다. 사이클을 확인하는 방법은 여러가지가 있지만 대표적으로 플로이드-워셜과 Union-find 가 있다. 구체적인 내용과 장단점은 다른 게시글을 통해 확인하고, Union-find에 대한 설명과 적용방법만 설명하겠다.
서로소 집합 알고리즘
서로소 집합은 공통 요소(교집합)이 없는 서로 다른 집합이다. 나누어진 원소들의 데이터를 처리하기 위한 자료구조가 서로소 집합 자료구조이다. 서로소 집합 자료구조는 union(합집합 연산)과 find(찾기 연산) 2개로 이루어져 있다. 보통 트리 자료구조를 이용하는 서로소 집합 자료구조에서 서로소 집합 계산 알고리즘은 다음과 같다.
- Union 연산 정보 중 1개를 확인하여, 서로 연결된 두 노드 A,B를 확인한다.
- 두 노드 각각의 루트노드를 알아낸다.
- 두 루트노드 중 작은 노드를 부모 노드라고 가정하고 연결시킨다.
- 이후 연산 정보를 순차적으로 받으면서 반복한다.
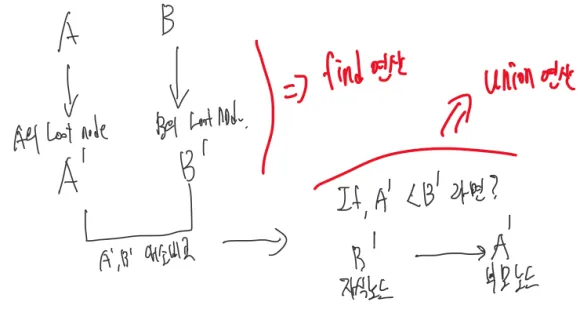
위는 find 연산과 union 연산을 나타내는 그림이다.
서로소 집합 알고리즘의 동작을 조금 더 자세하게 설명하면 다음과 같다.
- (노드의 개수+1)을 길이로 하는 부모 테이블을 만든다. 리스트의 원소값은 해당 인덱스값을 넣어주는데, 즉 모든 원소가 자기 자신을 부모로 가진다는 의미이다.
- union 연산 하나를 받아온다. 이를 통해 해당 노드의 부모 테이블 값을 변경해준다. 예를 들어 (1,4) 연산이 들어왔다면 4번 노드의 부모 노드는 4로 설정되어있었지만 이것을 1로 바꾸어준다. 연산을 받아오면서 반복한다.
- 만약 이후 (2,4)가 들어왔다고 가정해보자. 2번 노드의 부모 노드는 2인 반면 2번 과정으로 4의 부모 노드는 1이다. 따라서 더 큰 부모 노드를 가진 2번 노드의 부모 노드 값을 1로 바꾼다.
요약하자면
find연산 : A와 B 둘의 루트 노드 A’ 와 B’ 중 누가 큰가?
union연산 : A’와 B’ 중 작은 것이 큰 것의 부모노드가 된다.
이 두 가지 연산을 바탕으로 각 노드들의 부모 노드들이 누구인지 관계를 밝히는 알고리즘이 서로소 집합 알고리즘이다. 코드는 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
n, m = map(int, sys.stdin.readline().rstrip().split())
parent = [i for i in range(n+1)]
def get_parent(x):
if parent[x] == x:
return x
parent[x] = get_parent(parent[x]) # get_parent 거슬러 올라가면서 parent[x] 값도 갱신
return parent[x]
def union_parent(a, b):
a = get_parent(a)
b = get_parent(b)
if a < b: # 작은 쪽이 부모가 된다. (한 집합 관계라서 부모가 따로 있는 건 아님)
parent[b] = a
else:
parent[a] = b
def same_parent(a, b):
return get_parent(a) == get_parent(b)
ans = 0
for a, b, cost in arr:
if not same_parent(a, b):
union_parent(a, b)
ans += cost
print(ans)
위를 바탕으로 문제를 해결하자면, 우선 입력값을 받은 뒤 가중치를 기준으로 2차원 배열을 정렬한다. 그리고 부모를 표시하기 위한 배열을 생성한다. v+1까지인 이유는 1부터 v까지를 표시하기 위해 0번 index는 비우기 때문이다. 우선 부모를 표시하는 find함수 를 get_parent라는 이름으로 생성한다. 부모가 자기자신이면 함수를 종료하되, 그렇지 않으면 재귀를 통해 부모의 부모(조부모)를 타고 가서 끝까지 파악한다. 그 후 union함수를 union_parent라는 이름으로 생성한다. 상술했듯 작은 값을 큰 값의 부모로 설정하는 함수이다. 부모가 같은지 True/False를 반환하는 함수도 생성한다. 이 후 가중치에 따라 오름차순으로 정렬한 배열을 순회하며 부모가 다른 간선의 가중치만 더하기를 반복한다.
혹여나 이해가 되었다면 아래 부연설명을 꼭 읽어보길 바란다.
결과
이해
코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
import sys
v, e = map(int, sys.stdin.readline().rstrip().split())
arr = []
for _ in range(e):
a, b, c = map(int, sys.stdin.readline().rstrip().split())
arr.append((a, b, c))
arr.sort(key=lambda x: x[2])
parent = [i for i in range(v+1)]
def get_parent(x):
if parent[x] == x:
return x
parent[x] = get_parent(parent[x])
return parent[x]
def union_parent(a, b):
a = get_parent(a)
b = get_parent(b)
if a < b:
parent[b] = a
else:
parent[a] = b
def same_parent(a, b):
return get_parent(a) == get_parent(b)
ans = 0
for a, b, cost in arr:
if not same_parent(a, b):
union_parent(a, b)
ans += cost
print(ans)
부연 설명
사실 설명을 하기위해 공부를 하다보니, 부모 라는 개념은 트리 구조에서 상위 노드와 하위 노드의 계층이 존재할 때 사용하는 개념안데 여기서 사용하기 부적절하다는 생각이 들었다. 많은 블로그에선 부모 노드라고 표현하고 있긴 하다. 어떤 곳에선 비유적인 개념으로 사용한 것이라고 언급하긴 하지만..? 나는
부모가 같다 = 같은 집합에 속한다
라는 설명을 봤는데, 그럼 도대체 같은 집합이라는건 뭘까? 내가 내린 결론은 다음과 같다.
노드 A 와 노드 B를 잇는 간선이 존재한다면, 노드 A와 B는 같은 집합안에 포함된다. [A,B] 처럼. 이 간선에 이어서 B와 C를 잇는 노드가 생성된다면? 집합에는 B는 있지만 C가 없기 때문에 사이클이 생성되지 않고 집합도 [A,B,C] 가 되는 것이다. 여기서 C와 A를 잇는 새로운 간선을 추가하는 것부터 문제가 된다. 새로운 간선이 잇는 두 노드 A,C 둘 다 집합에 포함되어 있다. 따라서 이 간선이 추가되면 사이클이 생성된다는 것을 의미한다.
그럼 부모의 관점이 아니라 집합의 관점으로 다시 바라본다면?
union은 이름이 숫자인 두 노드 중 작은 값을 이름으로 하는 집합을 만드는 것이다. 두 노드 13과 27을 union연산을 기존처럼 한다면 27의 부모는 13이라는 결론이 난다. 바꿔 말하면 13과 27은
이름이 13인 집합에 노드 13과 27이 포함되는구나
라고 말할 수도 있는 것이다! 그래서 부모 = (속한 집합의 이름) 인 것이다.
결국, 말하고자 하는 바는
우리가 binary search tree 같은 트리구조에서 보는 부모-자식 구조와 여기서의 부모는 다르다
이다.