2023년 9월 8일 알고리즘 문제풀이
문제 1 백준 9273
1차 시도
나의 생각
결국 두 자연수 a,b에 대하여 1/n = 1/a + 1/b 가 성립해야 한다고 생각했다. 따라서 이 수식을 고쳐서
b = na/(a-n) 으로 만들었다. 이 함수를 a,b 에 대한 함수로 이해해보자. b-n = (n^2)/(a-n). 유리함수중에 분수 함수라고 할 수 있다. 점근선은 x =n, y = n이다. 아래와 같은 함수이다.
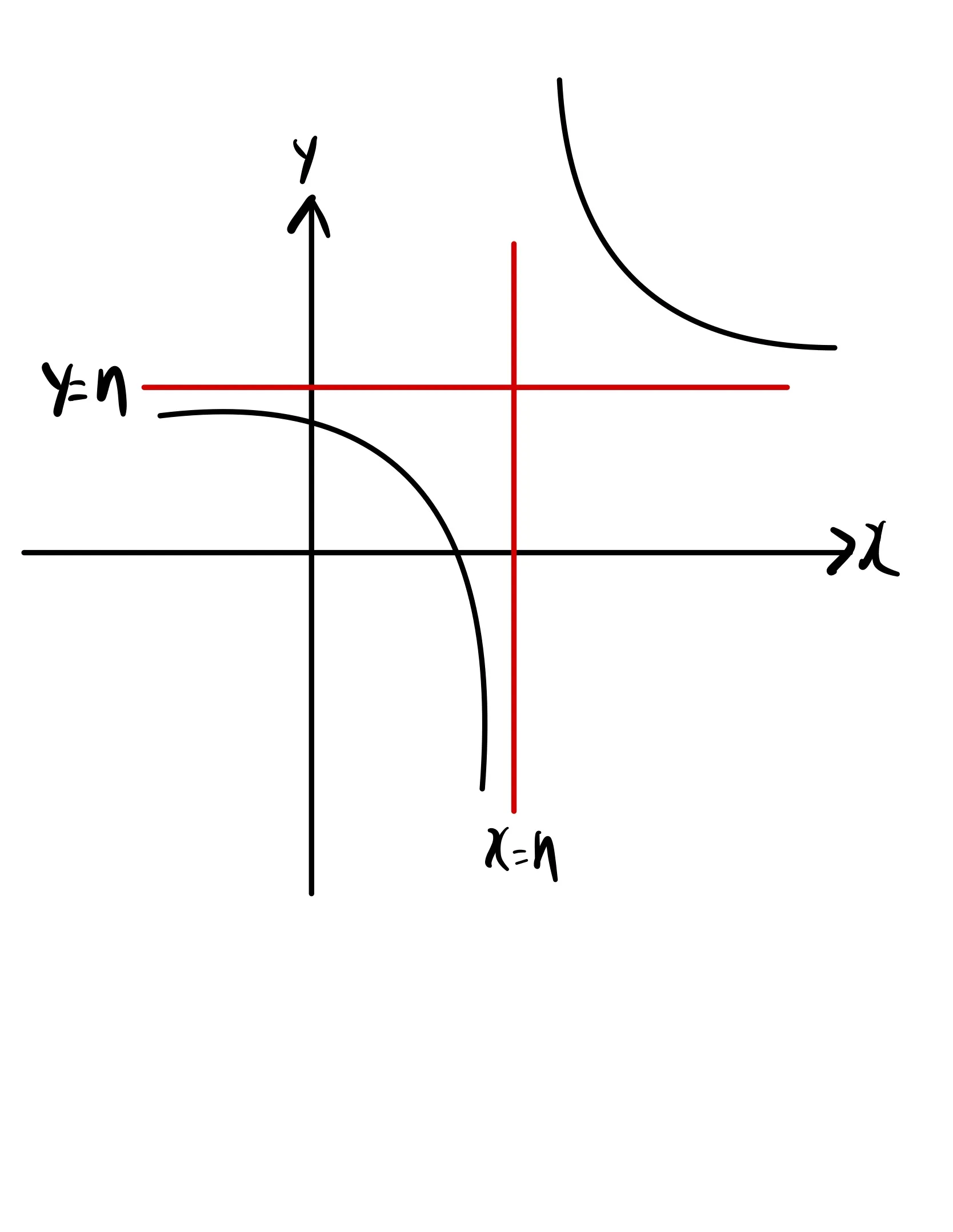
이 그래프에서 x,y가 모두 자연수인 함수 위 좌표를 찾았다. x가 0일 때 y가 n이다. x가 1이면 y는 자연수일 수 없다. 따라서 x가 2부터 1씩 증가하다가 y값이 음수면 멈췄다.
그 다음 x가 n+1값부터 증가하다가 결국 y는 n에 무한히 가까워진다. 따라서 y가 n+1보다 작아지면 그 이상은 무의미하다고 생각했다.
그런데 x,y가 뒤바뀐 것도 동일하게 처리해야 하는 조건을 세는게 쉽지 않았고, 위 로직도 만들기 쉽지 않았다..
결과
오답
코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
import sys
while True:
try:
o, n = map(int, sys.stdin.readline().split('/'))
cnt = 0
if n > 2:
x = 2
y = (n**2)/(x-n)+n
while y > 0 and x < n:
if not (n**2) % (x-n):
cnt += 1
x += 1
x = n+1
y = (n**2)/(x-n)+n
while (n**2)/(x-n) > 1:
if not (n**2) % (x-n):
cnt += 1
x += 1
print(cnt)
except:
break
2차 시도
나의 생각
이번엔 작은수부터 가지 말고 큰수부터 갔다. 이 수는 역수기 때문에 n보다 a,b 상수가 커야한다. 분모가 클수록 전체 수가 작아지기 때문이다. a와 b는 대칭이기 때문에 절반만 보면 된다고 생각했다. 만약 a,b가 2n이라면 어떨까? 1/a + 1/b는 딱 1/n이 된다. a,b,는 2n일 때가 절반 지점인 것이다. 여기부터 1씩 줄여나가기로 했다. 아까는 점점 숫자를 키웠지만 n이 작을떄의 값들이 헷갈려서 반대로 해버렸다. a는 2n+1 부터 1이 될때까지 줄이고 그때 b가 자연수인지 확인하면 된다.
기존 위 시도에서 만든 함수는 그대로 유지하여 나머지가 0일때만 계산하면서 순회했다. 그런데 pypy3로 제출하지 않으면 시간초과가 뜬다.. python으로 어떻게 풀 수 있을까..
결과
정답
코드
import sys
while True:
try:
one, num = map(int, input().split('/'))
cnt = 0
a = num*2+1
while a > num:
if not (num*a) % (a-num):
cnt += 1
a -= 1
print(cnt)
except:
break
문제 2 백준 9251
1차 시도
나의 생각
오랜만에 LCS라 생각해내는데 힘들었다.. 다시 안까먹기 위해 상세하게 개념을 설명해보겠다.
LCS는 Longest Common Subsequence 의 약자로 최장 공통 부분 수열문제이다. 두 수열의 공통된 부분 중 가장 긴 것을 찾는 것이다. 꼭 붙어있을 필요없이 순서만 맞으면 된다. 문제의 예시에서 ACAYKP와 CAPCAK 가 나왔는데 답은 ACAK이다. 두번째 수열에서 A와 C가 이웃되어 있지 않지만 상관 없다. 앞서 말했다 싶이 이웃하지 않고 A 뒤에 C, 그 뒤에 다시 A, 그 뒤에 K가 나오기 떄문에 성립한다.
이 문제를 푸는 방법을 요약하자면, 한글자씩 추가하며 모두 비교하는 것이다. ACAYKP와 CAPCAK로 생각해보자. ACAYKP 를 첫번째 단어, CAPCAK를 두번째 단어라고 지칭하겠다. 첫번째 단어 중 첫 글자인 A를 두번째 단어의 각 경우와 비교 한다. A와 C, A와 CA, A와 CAP, A와 CAPC, A와 CAPCA, A와 CAPCAK 를 모두 말이다. 그다음은? AC와 모두를 비교, ACA와 모두를 비교.. 이런 방식이다. 하지만 모두 비교해서 결과를 내기엔 너무 경우도 많고 복잡하니, 그전까지의 비교값을 통해 다음 비교를 위한 연산을 최소화하는 것이다.
피보나치 수열과 관련된 문제에서 DP는 1차원이였고, 재귀함수를 이용하지 않도록 수열의 각 항(parameter로 받은 값)의 반환값을 저장해둔 것이다. LCS문제에서는 2차원을 사용한다. 두 단어의 부분수열 중 길이가 i일 때와 j일 떄의 비교를 dp[i][j]로 저장해둔다. dp[1][1] 은 길이가 1인 두 부분수열을 비교한 것이다. 다시 말해 맨 앞글자 하나씩 비교한 것이다. 두 단어의 길이가 p,q일 때 dp[p][q] 는? 길이가 각각 p와 q인 부분수열을 비교한 것이다. 이는 그냥 수열 본인끼리 비교한것과 같은 의미다.
첫번째 단어 중 x만큼의 글자만 보고 있다고 생각해보자. 두번째 단어는 y만큼의 글자만 보고있다. 즉 첫번째 단어의 부분 수열중 길이가 x일 때, 두번째 단어의 부분 수열중 길이가 y일 때의 비교이다. 그냥 비교해도 되겠지만 앞서 말했다싶이 이전 것을 이용한다.
만약 첫번째 단어의 x번쨰 글자와 두번째 단어의 y번째 글자가 같다면 어떨까? 그럼 첫번째 단어에서 길이가 x-1인 부분수열, 두번째 단어에서 길이가 y-1인 부분수열을 비교할떄와 어떻게 다를까? 딱 1이 더해질 것이다. 이해가 안된다면, 임의의 두 단어가 있고 현재 이 두 단어의 LCS의 길이가 7이라고 해보자. 이제 양 쪽 단어 둘다 끝에 ‘T’라는 글자를 붙여주자. 그럼 당연히 LCS는 ‘T’가 추가되어서 1 늘어날 것이다. 첫번째 단어의 x번째 글자와 두번째 단어의 y번째 글자가 같다는 의미는 바로 이런 의미이다. x-1번째 까지 본 부분수열과 y-1번째 까지 본 부분수열의 끝에 같은 글자를 더해주었다는 것. 그래서 1이 늘어난다.
x번째 글자와 y번째 글자가 같지 않다면 어떨까? 그냥 넘어가선 안된다. 이 문제가 힘든 이유는 여기서 단순히 안늘어난다라고 결론내릴 수 없기 때문이다. 같지 않아도, LCS는 x-1 길이의 부분수열과 y-1 길이의 부분수열의 LCS보다 증가할 수도 있다. 반례를 만들어보겠다. ATESCBX , BESKKKK 라는 두 단어가 있다 가정하자. 현재 두 단어의 LCS는 ES이다. 즉 2글자이다. 첫번째 단어에는 K를 붙이고, 두번째 단어에는 Y를 붙여보자. ATESCBXK , BESKKKKY가 되었다. LCS는? ESK. 3으로 증가했다. 서로 다른 글자를 붙였는데 기존에 한쪽에만 있던 글자가 반대쪽에 붙음으로서 CLS가 증가한 것이다! 이 케이스를 어떻게 체크해야할까? x길이 부분수열과 y-1길이 부분수열, x-1길이 부분수열과 y길이 부분수열의 LCS 중 증가한 것이 있는지 확인해 보는 것이다. 글자 추가를 하나씩 해보면 된다.
ATESCBXK 와 BESKKKK : LCS는 ESK. 3이다
ATESCBX 와 BESKKKKY : LCS는 ES. 2이다
둘 중 변한 것, 다시 말해 최댓값으로 업데이트 하면 된다. 로직을 정리해보자
- 두 단어의 마지막 글자가 같다면?
- 두 단어에서 마지막 한글자씩 뺏을때 LCS의 길이에 +1을 해준다.
- 두 단어의 마지막 글자가 다르다면?
- 한 쪽 단어에만 추가했을 때 2가지 경우를 비교해서 최댓값으로 업데이트해준다.
이것을 코드로 정리해보자.
1
2
3
4
5
6
7
8
9
10
la = len(A)
lb = len(B)
for i in range(1,la):
for j in range(1, lb):
# 길이가 i인 부분수열의 마지막 글자 index는 i고
# 길이가 j인 부분수열의 마지막 글자 index는 j다.
if A[i] == B[j]: # 현재 부분수열의 마지막 글자가 같다면?
dp[i][j] = dp[i-1][j-1] + 1 # 한 글자씩 적었을 때보다 +1
else: # 같지 않다면?
dp[i][j] = max(dp[i][j-1], dp[i-1][j]) #한글자씩 뺏을때 중 큰값
추가로, 단어를 그대로 받으면 0번 index부터 글자를 시작해야 한다. 글자 비교를 통해 dp 2차원 배열을 만들어가는 과정에서 이전 index로부터 값을 받아오거나 비교에 사용하게 되는데 0번부터 시작하면 index가 범위 밖으로(-1을 지정해버린다) 나가버리다보니 꼬이게 된다. 따라서 index를 1부터 시작하기 위해 임의로 글자를 붙이거나, 리스트로 만들 때 영향없는 글자 하나를 추가하는 것이다.
표를 통해 한번 더 살펴보자.
| 없음 | B | BE | BES | BESK | BESKK | BESKKK | BESKKKK | BESKKKKY | |
|---|---|---|---|---|---|---|---|---|---|
| 없음 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| A | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| AT | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ATE | 0 | 0 | (가): 1(E) | 1(E) | 1(E) | 1(E) | 1(E) | 1(E) | 1(E) |
| ATES | 0 | 0 | 1(E) | (가): 2(ES) | 2(ES) | 2(ES) | 2(ES) | 2(ES) | 2(ES) |
| ATESC | 0 | 0 | 1(E) | 2(ES) | 2(ES) | 2(ES) | 2(ES) | 2(ES) | 2(ES) |
| ATESCB | 0 | 1(B) | 1(E) | 2(ES) | 2(ES) | 2(ES) | 2(ES) | 2(ES) | 2(ES) |
| ATESCBX | 0 | 1(B) | 1(E) | (나): 2(ES) | 2(ES) | 2(ES) | 2(ES) | 2(ES) | 2(ES) |
| ATESCBXK | 0 | 1(B) | 1(E) | 2(ES) | 2(ES) | (가): 3(ESK) | 3(ESK) | 3(ESK) | (나): 3(EKS) |
(가) : 이 부분들은 두 부분수열의 마지막 글자(방금 추가된 글자)가 같은 경우다. 따라서 하나씩 뺀 경우에서 +1을 한 것이다.
(나) : 두 부분수열의 마지막 글자가 같지 않지만, 하나씩 뺴서 비교한 결과 최댓값으로 업데이트 한 경우다. 굉장히 많지만 그 중 2개만 (나)라고 표시했다.
결과
정답
코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import sys
a = '0' + sys.stdin.readline().rstrip()
b = '0' + sys.stdin.readline().rstrip()
la = len(a)
lb = len(b)
dp = [[0 for _ in range(lb)] for _ in range(la)]
for i in range(1,la):
for j in range(1,lb):
if a[i] == b[j]:
dp[i][j] = dp[i-1][j-1] + 1
else:
dp[i][j] = max(dp[i-1][j],dp[i][j-1])
print(dp[-1][-1])
문제 3 백준 9252
1차 시도
나의생각
기존 LCS는 숫자로 표시하면 됐었다. 이젠 수열도 표시해야하니 배열에 저장할 때 LCS도 저장해주면 된다. 코드가 좀더 추가될 뿐 어렵진 않다!
같을 떄 1을 더했다면 이번 문제에선 글자를 추가해주자.
다를때는 큰 값으로 업데이트했다면, 이번 문제에선 더 긴 길이의 부분수열로 업데이트해주자.
다만 처음에 마지막 출력부분에서
1
2
3
print(len(dp[-1][-1]))
if len(dp[-1][-1]):
print(dp[-1][-1])
이렇게 작성했더니 시간초과가 났다.. 아슬아슬했다!
결과
정답
코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
import sys
a = '0' + sys.stdin.readline().rstrip()
b = '0' + sys.stdin.readline().rstrip()
la = len(a)
lb = len(b)
dp = [['' for _ in range(lb)] for _ in range(la)]
for i in range(1,la):
for j in range(1,lb):
if a[i] == b[j]:
dp[i][j] = dp[i-1][j-1] + a[i]
else:
if len(dp[i-1][j]) >= len(dp[i][j-1]):
dp[i][j] = dp[i-1][j]
else:
dp[i][j] = dp[i][j-1]
ans = dp[-1][-1]
if len(ans):
print(len(ans),ans,sep='\n')
else:
print(len(ans))